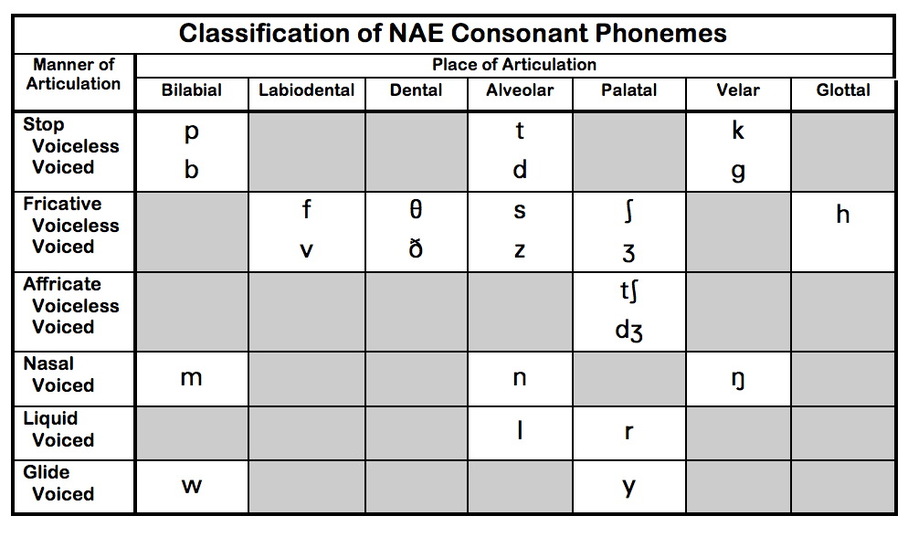
| Description: | This data set is a subsample of the data used in the paper
Dual-domain Hierarchical Classification of Phonetic Time
Series. Each series is extracted from the segmented audio
collected from Google Translate, oxforddictionaries.com and the
Merrriam-Webster online dictionary. Each of these sources have
different features. Audio files collected from Google translate,
Oxford, and Merrriam-Webster dictionaries are recorded at 22050,
44100 and 11025 samples per second respectively. All of them have
male and female speakers in different ratios. The Oxford dictionary
includes British and American accent pronunciation for each word.
After data collection, they segment waveforms of the words to
generate phonemes using the Forced Aligner tool from the Penn
Phonetics Laboratory.
|